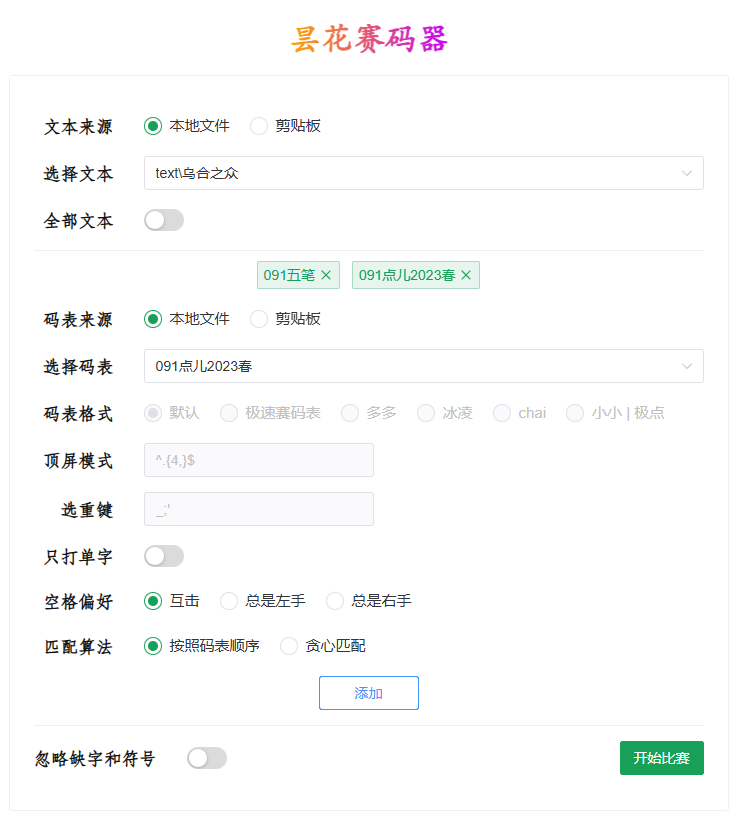
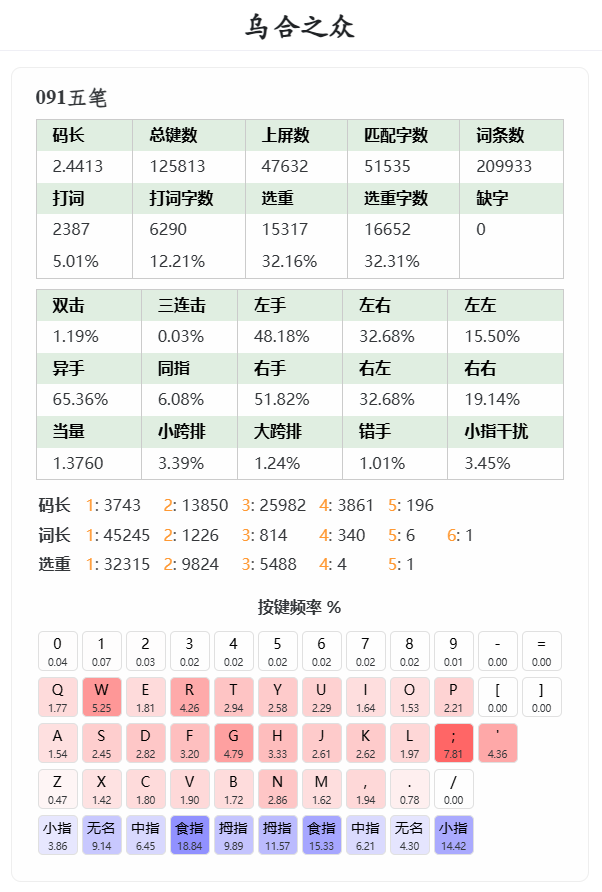
输入法评测工具——昙花赛码器
目录
“赛码器”是一种用于评估不同输入法方案(主要是码表类方案)之间“性能”差异的工具。
如何评估码表类输入法方案
静态分析
根据静态码表进行分析,一般会区分单字和词组。常见工具如下:
动态分析
分析码表在特定某一篇或多篇文章的表现。常见工具如下:
- 自由输入法编码工具箱 by 獨来 du 往
- 极速赛码器 by 消逝
最经典也是最常用的评测工具,界面美观。
需要转换码表格式且只支持 UTF-16LE 编码格式,性能较低。 - 昙花赛码器 by nopdan
Golang 编写,性能最优,同时支持命令行和 server 端,支持多种码表格式,自动识别编码格式。 - 形码盒子 by yb6b
网页上传,即点即用,性能较优,支持多种码表格式。
为什么要写昙花赛码器
主要是针对「极速赛码器」的改进。
- 性能,这是最主要的原因。「极速赛码器」对系统资源利用极低,内存只用到 10+MB,CPU 占用百分之几,性能低下,10w 字文章要几十秒,上百万文章基本不可用。
- 易用性,「极速赛码器」需要手动转换码表格式,且对编码格式有限制。
- 学习 Golang,这是我用 Golang 写的第一个项目。
赛码器架构设计与性能优化
昙花赛码器(Gosmq)从设计之初就注重性能,并且在开发过程中不断进行优化。其核心目标是实现对多个码表和多篇文章(m:n)的同时赛码。
码表处理
为了提升码表的构建和加载速度,昙花赛码器采用了自定义的赛码表格式。这种格式针对赛码场景进行了专门优化,能够快速加载和解析码表,减少初始化时间。
当然,其他格式如极点、rime 等同样支持,在第一次使用其他格式的码表会自动转换为专用的赛码表格式,下次使用就能得到加速。
文章处理
通过流式读取和文本分段技术,结合 Golang 的协程(goroutine)能力,充分利用了多核 CPU 的性能。
- 流式读取:采用流式读取方式处理文章,根据文件大小智能分配缓冲区尺寸,避免一次性加载大文件导致的内存占用过高问题。
- 文本分段:将文章分段处理,结合协程并发执行,充分利用多核 CPU 的计算能力。
文本分段算法:
func (t *Text) Iter() ([]byte, error) {
if t.reader == nil {
return nil, io.EOF
}
if t.size < t.bufSize {
return io.ReadAll(t.reader)
}
buffer := make([]byte, t.bufSize, t.bufSize+4*1024)
n, _ := io.ReadFull(t.reader, buffer)
buffer = buffer[:n]
for {
b, err := t.reader.ReadByte()
// EOF
if err != nil {
return buffer, io.EOF
}
// 防止切到 utf-8 编码中间
if b < 33 {
// 控制字符 直接切分
return buffer, nil
} else if b < 0b11000000 { // 0b0xxxxxxx || 0b10xxxxxx
// ascii 码,或者 utf-8 编码后几位
buffer = append(buffer, b)
continue
} else { // 0b11xxxxxx
// utf-8 前缀,回退,之后读取 rune
_ = t.reader.UnreadByte()
break
}
}
for {
r, _, _ := t.reader.ReadRune()
// 控制字符 直接切分
if r < 33 {
return buffer, nil
}
switch r {
case '“', '‘', ':', '《':
_ = t.reader.UnreadRune()
return buffer, nil
}
b := util.UnsafeToBytes(string(r))
// 超过 buffer 容量直接返回,减少切片扩容
if len(buffer)+len(b) > cap(buffer) {
_ = t.reader.UnreadRune()
return buffer, nil
}
buffer = append(buffer, b...)
switch r {
case '。', '?', '!', '》':
return buffer, nil
}
}
}字符串匹配算法
使用基于哈希的字典树(trie),兼具构建速度、匹配速度和内存占用。
用户交互与数据展示
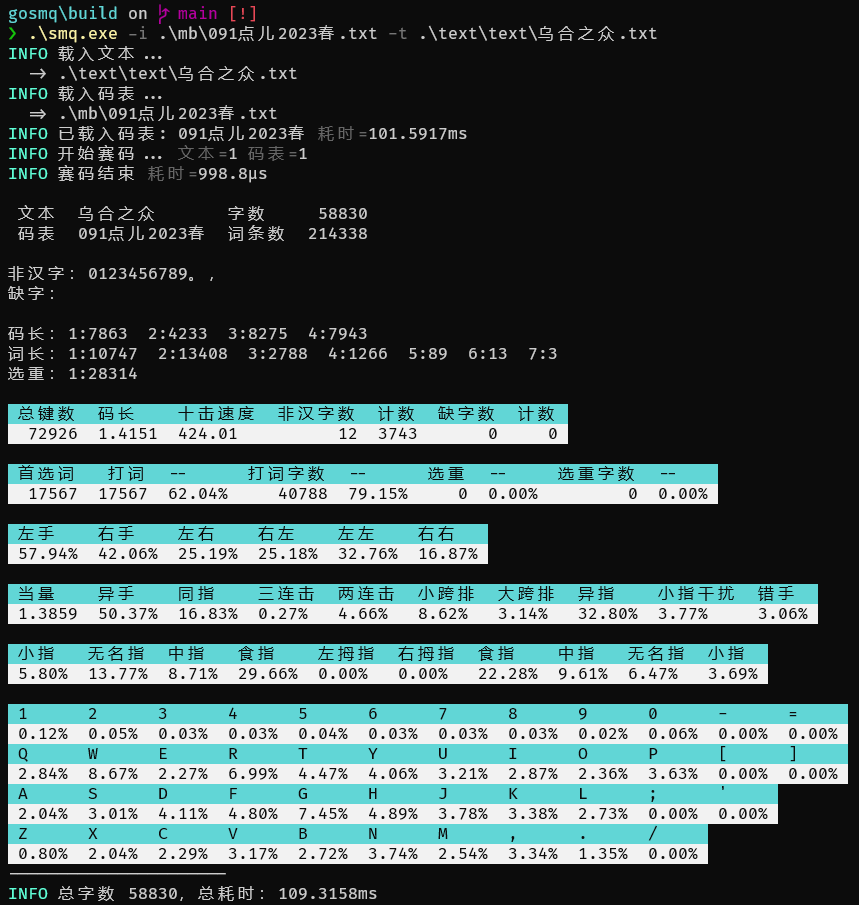
命令行
使用 go-pretty 包美化输出结果。
web
使用 bunjs + vue + naive-ui,配合 go1.16 新特性 go embed